APARSEN held a series of webinars on emerging topics/results in the project. These webinars all had a similar setting and format and took place as virtual meetings with APARSEN partners and external stakeholders participating. Their aim was to present some of the results of APARSEN when a topic milestone were reached and to foster discussions with stakeholders outside of APARSEN. Participation was free, no registration was required!
APARSEN webinars
APARSEN Virtual Centre of Excellence – 10th December
A Common Vision for Digital Preservation – 14th October
Interoperability of Persistent Identifiers – 25th June
Storage Solutions for Digital Preservation – 14th April
Certification of Digital Preservation Repositories – 9th December
Interoperability and Intelligibility Strategies – 8th November
Sustainability and Cost Models for Digital Preservation – 13th June
Virtual Centres of Excellence – 2 – 16th October
Virtual Centres of Excellence – 1 – 12th September
Securing Trust in Digital Preservation – 11th July
APARSEN Virtual Centre of Excellence.
Wednesday 10th December 2014 14:00 – 16:00 CET
The APARSEN project, bringing together more than 30 partners and finishing by the end of this year, has worked 4 years towards the launch of a Virtual Centre of Excellence for Digital Preservation.
The VCoE will help to avoid further fragmentation in the area of Digital Preservation by providing technical methods and tools as well as DP implementation support services, consultancy and training. The VCoE Unique Value Proposition is based on two pillars:
- We offer a coherent approach based on value and which can be applied to any kind of digital objects;
- We are backed by the combined experience of the DP pioneers both in the research field and, more importantly, as worldwide earliest adopters of DP practices.
Program:
Speakers:
- Simon Lambert (STFC) – presented by Eefke Smit (STM): It all started in 2004; how we got here.
[Download not found] - David Giaretta (APA): The VCoE: what it offers
[Download not found] - Jamie Shiers (CERN) guest speaker: Data Preservation and the challenges of the next 10 years
[Download not found] - Michel Drescher (EGI) – presented by David Giaretta (APA): guest speaker: EGI’s community infrastructure and the VCoE
[Download not found]
See below for a recording of Michel’s talk at the APA conference
Moderator: Eefke Smit (STM)
A video of the meeting is available at
Also see Michel’s presentation at the APA conference:
The meeting was a web-meeting and took place on megameeting: Participation was free, no registration required: http://alliancepermanentaccess.megameeting.com/guest/#&id=36245
Facebook: https://www.facebook.com/events/1486600554949260/
Twitter: https://twitter.com/APARSENproject
[reveal heading=”⇒ Click here for a Short summary of presentations and discussion“]
Short report of the APARSEN webinar on December 10, 2014, topic:
Attendees: throughout the whole webinar a total of 24 people have logged on individually, during most part of the webinar the average number of simultaneous attendees via a log-in was around 17. Two thirds of the audience were people from outside project-APARSEN. One third of the audience were persons related to APARSEN partner organisations. Affiliations from attendees ranged from many universities and libraries, mostly across Europe.A total of 14 tweets were exchanged during the webinar, captured at the end of this report.
Report by Eefke Smit, STM, also moderating the webinar.
Keywords: Digital Preservation, Consultancy, Tools and Services, Training, defragmentation, holistic approach, certification, Centre-of-Excellence.
Short summary of presentations and discussion:
In the introduction prepared by Simon Lambert (STFC, project administrative coordinator) and presented by Eefke Smit (STM), it was explained how the journey towards the APARSEN Centre of Excellence started 10 years ago at the 2004 conference on Digital Preservation in The Hague where a task force was formed for Permanent Access. This led to the establishment of the Alliance for Permanent Access (APA) and in 2011 to the EU-funded APARSEN-project. The motivation behind APARSEN is reducing the current fragmentation in digital preservation initiatives by means of ensuring a broad scope, inclusion of a great variety of application domains, exploring many different aspects of the problem and bringing together a wide array of approaches and techniques. The project brings together 31 partners from a wide spectrum of backgrounds and therefore allows insight into the many ongoing initiatives and approaches currently. The results of this will come together in the Centre of Excellence with a more holistic approach of digital preservation as an enabler of value.
The Centre of Excellence will live beyond the life of project-APARSEN and be a focal point for available tools, services, consultancy and training. The 31 partners in APARSEN will continue to cooperate to further develop the excellence, structuring it and spreading it. In the changing landscape around data preservation, explorations have started to find a good home for the APARSEN VCoE withint the Research Data Alliance. All in all, the past 10 years were an exciting journey that will reach its finish in a few weeks, while a new journey is about to start.
Presenting the APARSEN Virtual Centre of Excellence (VCoE), David Giaretta, Director of APA, gave an overview what kind of solutions the VCoE intends to offer, in terms of consultancy, tools and services and training. Challenges are the many different types of digital objects, the variety in tools and approaches and simply the many lists available everywhere. An integrated vision on digital preservation is key, and mainly how the preservation actions create new value for reuse. Preservation actions need to take into account more considerations than just ‘migrate or emulate’; it must look for evidence that chosen tools and services will do what is necessary in the light of all possible future threats. Evidence for the effectiveness of tools has been gathered by APARSEN and APA in test beds and from use cases. An overview can be found here: APA/APARSEN list of tools: http://www.alliancepermanentaccess.org/index.php/tools/tools-for-preservation/ In a similar fashion, overviews are available of solution providers, of glossaries and standards on the APA and APARSEN website. Training facilities are offered online via e-learning modules as well as via face-to-face trainings. The test audit findings offer a solid basis for many other repositories to improve their own operations. The most commonly found gaps were the absence of adequate Archival Information Packages, lack of a well-defined designated user community and lack of proper Representation information or metadata. There is also a general lack of hand-over plans, for which orchestration services are foreseen, to help repositories find the right partners for this.
In summary: the VCoE will be around consultancy, tools and services and training. It will offer consultancy to properly define the solution needed, help select the proper tools and services and offer training to get the right people in place.
Jamie Shiers, guest speaker from CERN, presented the challenges of the next 10 years for Digital Preservation in “Data Preservation at the EXA-scale and beyond”. The main question in his talk was that long-term sustainability is still a technical issue and assuming that the Business Cases and Cost Models will be developed, and that there is sufficiently agreed funding: can the service providers guarantee a multi-decade service? And: is this realistic? Is this even desirable?
In his vision, the objective for 2020 should be to have all archived data – e.g. that described in DPHEP Blueprint, including LHC data – easily findable, and fully usable by designated communities with clear (Open) access policies and possibilities to annotate further. There should be wide availability of best practices, tools and services, well run-in, fully documented and sustainable; built in common with other disciplines, and based on standards. For the High Energy Physics domain (HEP), CERN is working on a so-called “HEP FAIRport”: to make available data Findable, Accessible, Interoperable, and Re-usable. A portal, through which data / tools can be easily accessed.
Certification of repositories is key, says Shiers: it is needed to help align policies and practices across sites, to improve reliability, to eliminate duplication of effort, to reduce “costs of curation”, and to help address the “Data Management Plan” issue required by Funding Agencies. Overall, certification of repositories will increase “trust” with “customers” for the stewardship of the data.
In summary, Jamie Shiers emphasized how next generation data factories will bring with them many challenges for computing, networking and storage, how Data Preservation – and management in general – will be key to their success and must be an integral part of the projects: not an afterthought. And last but not least: raw “bit preservation” costs may drop to
~$100K / year / EB over the next 25 years, but that does not solve everything, there is more to Digital Preservation than storage costs.
Michel Drescher, guest speaker from EGI, delivered a talk, presented by David Giaretta, on “EGI’s community infrastructure and the VCoE”. His full talk can be viewed here: https://www.youtube.com/watch?v=NPGDzExLoro
The EGI, or European Grid Infrastructure is based on Open Data, Open Access and Open Science and in this context EGI wishes to support digital preservation services in Europe. They assemble a federation of data services via a cloud-based set-up. A MoU was signed between EGI and APARSEN to ensure consultancy and training services, capture and analysis of requirements, define and deploy APA ICT services through EGI channels, and find viable business models for sustainable preservation services. Future opportunities will be explored together.
In the research data value chain, preservation services will be offered via a common service platform.
The EGI will act as a collaboration to enhance active Data Management plans, consistent Metadata capture/creation/sharing, automated data provenance capturing, cross-domain persistent identifier interoperability and data delivery and information packaging tailored to the user. Also Michel Drescher emphasized in his slides the importance of certification of Digital Preservation Repositories.
Report by ES, 12 December 2014
TWEETS at APARSEN webinar 10 December 2 pm.
APARSEN @APARSENproject · 2 u2 uur geleden
…. in any case SELECTION or APPRAISAL for digital contents is mandatory !!! we can never preserve alll what we are producing …
0 antwoorden0 retweets0 favorieten
Beantwoorden
Retweeten
Favoriet
Meer
APARSEN @APARSENproject · 2 u2 uur geleden
it is fundamental to understand costsfor maintaining so large digtial archives before asking who will do and pay for that …
0 antwoorden1 retweet0 favorieten
Beantwoorden
Retweeten1
Favoriet
Meer
APARSEN heeft geretweet
4C Project @4c_project · 2 u2 uur geleden
@APARSENproject #4ceu project can help organisations understand those costs: http://www.curationexchange.org/ #apawebinar
0 antwoorden3 retweets0 favorieten
Beantwoorden
Retweeten3
Favoriet
Meer
APARSEN @APARSENproject · 2 u2 uur geleden
the amount of data some ccentres are producing is impressive … and very expensive for the user comunity …
0 antwoorden0 retweets0 favorieten
Beantwoorden
Retweeten
Favoriet
Meer
APARSEN @APARSENproject · 3 u3 uur geleden
actually only few people realize that digital contents need care to be preserved in future … digital contents we produce can last shortly!
0 antwoorden0 retweets1 favoriet
Beantwoorden
Retweeten
Favoriet1
Meer
APARSEN @APARSENproject · 3 u3 uur geleden
Next talk of today: David @apadirector about what the VCoE offers #webinar
0 antwoorden0 retweets0 favorieten
Beantwoorden
Retweeten
Favoriet
Meer
APARSEN @APARSENproject · 3 u3 uur geleden
To learn more join FREE #webinar now: …https://alliancepermanentaccess.megameeting.com/meeting/?id=596-36245 …
Meer foto’s en video’s bekijken
0 antwoorden0 retweets0 favorieten
Beantwoorden
Retweeten
Favoriet
Meer
APARSEN @APARSENproject · 3 u3 uur geleden
Smit: #digitalpreservation is an enabler of value @APARSENproject #webinar
0 antwoorden0 retweets0 favorieten
Beantwoorden
Retweeten
Favoriet
Meer
APARSEN @APARSENproject · 3 u3 uur geleden
First talk of today: Eefke Smit about how all started @APARSENproject #webinar
0 antwoorden0 retweets0 favorieten
Beantwoorden
Retweeten
Favoriet
Meer
APARSEN @APARSENproject · 4 u4 uur geleden
Join APARSEN webinar now …https://alliancepermanentaccess.megameeting.com/meeting/?id=596-36245 …
0 antwoorden0 retweets0 favorieten
Beantwoorden
Retweeten
Favoriet
Meer
APARSEN @APARSENproject · 9 dec.
Last chance to learn from #APARSEN Virtual Centre of Excellence. Join the #webinar 10 Dec @ 14h: http://goo.gl/2N5P25 #DigitalPreservation
0 antwoorden2 retweets0 favorieten
Beantwoorden
Retweeten2
Favoriet
Meer
APARSEN @APARSENproject · 8 dec.
APARSEN Webinar on VCoE launch. Wednesday Dec 10 at 14CET http://www.alliancepermanentaccess.org/index.php/2014/11/21/webinar-on-vcoe-launch/#.VIV6McdtcgM.twitter …
0 antwoorden0 retweets0 favorieten
Beantwoorden
Retweeten
Favoriet
Meer
APARSEN @APARSENproject · 4 dec.
#WEBINAR: Last chance to learn from #APARSEN Virtual Centre of Excellence. Info here: http://goo.gl/2N5P25 #digitalpreservation
0 antwoorden6 retweets3 favorieten
Beantwoorden
Retweeten6
Favoriet3
Meer
APARSEN @APARSENproject · 4 dec.
NEW DATE:Webinar on VCoE launch http://www.alliancepermanentaccess.org/index.php/2014/11/21/webinar-on-vcoe-launch/#.VIA5WiccBfU.twitter …
0 antwoorden0 retweets1 favoriet
Beantwoorden
Retweeten
Favoriet1
Meer
[/reveal]
A Common Vision for Digital Preservation
14th October 2014, 15:00CET, 2 pm UK time, 9 am East Coast US. The webinar is scheduled to last 2 hours.
A Common Vision for Digital Preservation is the corner stone in the APARSEN project. During the past 4 years the 31 partners in the project have been developing a common vision that underpins the activities of the Centre of Excellence for Digital Preservation that will be launched on 22 October in Brussels. The Common Vision describes the key-players in this environment, their needs as well as the key-objectives, key-areas and the key-target groups for Digital Preservation activities and how to reach these.
Join this webinar to learn more about the core building blocks in the common vision such as trust, usability, sustainability and access and how it translates into workable solutions for the interoperability of persistent identifiers, storage solutions, certification of trusted repositories and business models. Get a better understanding of the offerings from the new Centre of Excellence. A training portal will provide over 40 modules that will help bring expertise, skills and services for digital preservation to a higher level.
- Simon Lambert, SFTC: “A Common Vision as part of the APARSEN project – how we got here“
- David Giaretta, APA: “The Common Vision of APARSEN – An Integrated view of digital preservation: main building blocks”
- Ruben Riestra, INMARK: “Spreading the Common Vision: outreach and marketing“
- Gerald Jäschke, GLOBIT: “Training Portal and the Common Vision”
- Kevin Ashley, DCC: “The 4C project Roadmap, process and outcome“
Moderator: Eefke Smit (STM)
A video of the meeting is available at TBS
Interoperability of Persistent Identifiers
25th June 2014
In the current Web environment, many initiatives have been launched for Persistent Identifiers and a variety of different communities are working with their own set of schemas and resolution services. For digital preservation it is of upmost importance that Persistent Identifiers schemes remain operable in the future and become interoperable among each other in order to ensure long-term accessibility, exchange and reuse of scientific and cultural data. In the Webinar experts will present different approaches to defragment the current situation and potential benefits for users of implementing services across PI domains and communities. These results will feed into the Virtual Centre of Expertise network under development by the APARSEN project.
The speaker’s programme was:
- Maurizio Lunghi & Emanuele Bellini, Fondazione Rinascimento Digitale: “A model for interoperability of PI systems and new services across domains“
- Sunje Dallmeier-Tiessen & Samuele Carli, CERN: “Implementation of persistent identifiers in a large scale digital library”
- Juha Hakala, Finnish National Library: “Revision of the URN standards and its implications to other PIDs”
- Anila Angjeli, Bibliotheque Nationale de France, ISNI consortium: “ISNI- abridge PID, a hub of links”
- Laure Haak, ORCID: “Connecting persistent identifiers for people, places, and things: ORCID as an information hub“
- Barbara Bazzanella, University of Trento: “The Entity Name System (ENS): a technical platform for implementing a Digital Identifier Interoperability Infrastructure”
- David Giaretta, APA: “The APARSEN Virtual Centre of Expertise”
Moderator: Eefke Smit (STM Association)
A video of the meeting is available at https://dl.dropboxusercontent.com/u/6959356/APARSEN/webinar/PI-Webinar-201406.mp4
[reveal heading=”⇒ Click here for a Short summary of presentations and discussion“]
- In her introduction as moderator, Eefke Smit (STM) explained how the general defragmentation objective of project-APARSEN for Digital Preservation policies and action, is of particular importance in the area of Persistent Identifiers. Many communities and initiatives have launched their own identifiers system, whereas for Digital preservation it is paramount that identifiers systems can be understood and re-used in different environments and contexts.
Within the APARSEN project an Interoperability Framework for different Persistent Identifier (PI) Systems is being developed. During the webinar, the model for this was explained and several guest speakers gave their perspective on what it can contribute to their own efforts. There were guest speakers from ISNI, ORCID, URN next to three speakers from within the APARSEN project: FRD, CERN and University of Trento. - Maurizio Lunghi, Fondazione Rinascimento Digitale in Italy presented the work on the APARSEN Interoperability Framework. The idea behind this IF (demonstrator available on http://93.63.166.138/demonstrator/demo7) is to have an open model that does not interfere with the ID-systems in question. It uses Linked Open Data to achieve the objective that descriptive information of digital objects in identifiers systems can be compared and exchanged. Aims in the development were that it should be easy to use and does not interfere into any system itself by applying distributed queries. It makes information of different PI systems (or PI domains) accessible in the same way. The Interoperability Framework was based on a list of assumptions and number of trust criteria, such as that PI systems must apply general trust criteria (having registration agencies, a resolver available on the web, etc) and that an entity exists at least in one ID-system or domain. Identification of the relationships between entities and/or actors are delegated to the ID systems in question.
On that framework many new added value services across different PI domains are implementable (that is not possible at the current state-of-art), Lunghi presented the first two for PI for digital objects and PI for people.
The Interoperability Framework demonstrator is available here: http://93.63.166.138/demonstrator/demo7/
The demonstrator will be used to test its feasibility, to identify the elements that need refinement and to measure user satisfaction. - Sunje Dallmeier-Tiessen & Samuele Carli from CERN gave their perspective on how to implement persistent identifiers in a large scale digital library (INPSIRE-HEP), containing over a million records, ranging from publications, preprints, data and technical reports to computer code, authors, etc. Author pages (over 300.000) are the spine of the system. Disambiguation of authors happens automatically and is checked via crowd sourcing. Via an ontology, links between persons, data and publications can be shared. Challenges at CERN have to do mainly with scaling; all data should be available in a SPARQL store, but exporting from INSPIRE and importing to the store can take weeks and stores are showing scalability issues when run on commodity hardware. This poses a challenge to keeping this store up-to-date.
- Juha Hakala, Finnish National Library has been working with URN standards as a PID system and investigate its compatibility to other PID systems. For interoperability, three conditions need to be met: syntax (can they be queried in the same way), semantics (aligning resolution services) and pragmatics (what is identified, is there any overlap). Most of the current ID systems were developed during the nineties. In itself it would not be too complicated to combine them all in one registry and such a service registry would help in guaranteeing the interoperability of services. Existing semantics and syntax could be used to identify new services.
- Anila Angjeli, Bibliotheque Nationale de France, ISNI consortium provided an overview of the current state-of-the art of ISNIs and how this PID facilitates a hub of links. ISNI is the International Standard Name Identifier (ISO 27729) that can be used for person names and organisation names. Currently, more than 8 million ISNIs are registered. Another 9 million still have to be assigned. The assignment must be unique, authoritative, trustful and persistent. ISNI aims to be an Identifier Hub and works together with ORCID, ODIN, ProQuest and also with many organisations who manage text rights, music rights and libraries. Proper data curation is the corner stone of the system. At the end of her talk, Angjeli confirmed that the IF system as developed in APARSEN would be completely compatible with the ISNI system.
- Laure Haak, of ORCID presented ORCID (orcid.org), a trusted persistent identifier for researchers and contributors. The ORCID Registry is an information hub, linking identifiers people, places and things. ORCID provides an open Registry and Web services to connect researchers with their works, organizational affiliations, and other person identifiers. Embedded APIs and common definitions enable interoperability and exchange between research data systems. Collaboration with Datacite on the ODIN Project (odin-project.eu/) has produced data linking tools, including tools that allow users to link their ORCID record with their datasets, with their ISNI, and with books. ORCID meets the trust criteria for persistent identifiers recommended by APARSEN. In addition, ORCID works with the community to ensure interoperability: the ability to resolve and link data entities (persons, data, things), open and shared definitions, ontologies, and exchange standards to define relationships and properties, and embedding of persistent identifiers in research workflows and data systems, such as manuscript submission and funding requests and proposals.
- Barbara Bazzanella, University of Trento presented the “The Entity Name System (ENS)” which has been developed as a technical platform for implementing a Digital Identifier Interoperability Infrastructure. In her talk she presented the main differences between so-called ‘Cool’ ID-systems and the more traditional Persistent Identifier systems. Cool URIs are based on robust web-technology, require no central management agency, no central system, are simply aimed at publishing and connecting structured data on the web. PIDs are enabling long term access and re-use, apply unique and trustful identifiers only, require registration agencies, formal commitment and trusted authorities in charge. Both systems have their drawbacks: Cool URIs are not unique and can have different identifiers for the same entity. PID’s are unique but require management and a resolution system, and usually a sustainable business model for managing them long-term. PID’s cause fragmentation and are a challenge to interoperability. Cool URIs work always but lack many long-term preservation aspects because of their decentralised nature. The Entity Name System (ENS) aims to provide a technical platform to reconcile the two different approaches by matching and mapping the IDs of both systems. ENS services, developed at the University of Trento, would provide storage, mapping, matching and lifetime management.
ENS would help bridge the gap between Cool URIs and other PID systems. Third party services can be built on top of the ENS-infrastructure, making it a neutral ID-management system. - In his closing remarks, David Giaretta, Director of APA, in particular stressed the importance, also in the context of APARSEN, how an Interoperability Framework such as described and developed within WP22 of APARSEN and presented by Maurizio, creates a whole new space for building new services for digital preservation. The Interoperability Framework system is simple and based on standard technologies, it is suitable for any PI system provided it respects the trust criteria defined by the expert workgroup. The other speakers who introduced their PI systems (ISNI, ORCID, ENS, CERN), all provided examples that fit well with the IF model proposed by APARSEN. Their applications would benefit a lot from a wide implementation of this model, confirming the validity of the approach used by the WP 22 partners. Regardless of the service that different projects propose, the implementation of the APARSEN open model would create conditions for open cooperation suitable to all the PI systems and defragmenting the current situation.
The open model of the APARSEN Interoperability Framework would create conditions for open cooperation, open to all the PI systems and not only to some.
[/reveal]
Storage Solutions for Digital Preservation
14th April 2014
Storage is a central component in any preservation solution, and requires special functionalities in order to adequately address the need of a preservation system. Partners’ needs for storage may vary substantially, e.g. in required capacity, number of objects, size of a typical object, geographical locations. Furthermore, depending on the nature of the data and its usage pattern, performance needs may vary greatly. New technological approaches are required that help bridge the observed gaps in requirements collection, design phase and quality assessment process of the storage architectures. Within APARSEN use cases were studied and a survey was undertaken to make an in-depth inventory of DP-risks and DP-options for different storage situations. This APARSEN webinar provides recommendations towards adopting storage solutions that can better serve digital preservation.
The speaker’s programme was:
- Simon Lambert, APARSEN Coordinator: “APARSEN and why Storage Solutions are important in Digital Preservation”
- Silvio Salza, Consorzio Interuniversitario Nazionale per l’Informatica (CINI): “Survey on Italian preservation repositories”
Download: [Download not found] - Jeffrey van der Hoeven, The National Library of the Netherlands (KB): “The use case at the National Library of the Netherlands”
Download: [Download not found] - EUDAT SPECIAL GUEST SPEAKER – Mark van de Sanden: “The EUDAT approach regarding Storage Solutions”
Download: [Download not found] - Julio Carreira, European Space Agency (ESA): “RSS Data-farm: from local storage to the cloud”
Download: [Download not found] - David Giaretta, APARSEN project Manager: “Concluding remarks and recommendations, what this means for APARSEN”
Moderator: Eefke Smit (STM)
[reveal heading=”⇒ Click here for a Short summary of presentations and discussion“]
- In his introduction, Simon Lambert (STFC, project administrative coordinator) explained how proper storage solutions are core to good digital preservation. He looked at how they contribute to the criteria for a trusted digital repository, and outlined some of the issues that arise such as scalability and growth overtime, migration, redundancy, security and online versus offline storage. He explained that APARSEN has produced three public reports on storage solutions and scalability.Within APARSEN the approaches of several partners have been compared and analysed, from survey material recommendations have been drafted and a separate work package has explored approaches to manage scalability, together with project Scape.In its aim to overcome fragmentation, Simon noted how useful it is to have such a diversity of partners within APARSEN, as many different approaches could be compared in a sensible way.In the following presentations, the APARSEN speakers elaborated on:
- The Italian situation, based on an extensive survey (Silvio Salza)
- The case study of the Dutch National Library KB (Jeffrey van der Hoeven)
After which two guest speakers gave the view from their own background:
- EUDAT’s approach to storage solutions (Mark van de Sanden)
- ESA’s explorations into cloud storage (Julio Carreira)
The webinar ended with concluding remarks on
- Recommendations from APARSEN ( David Giaretta)
- Silvio Salza of CINI in Italy presented the results from a survey in Italy about the current situation for long term storage solutions. 8 Large repositories were surveyed. Roughly half of the surveyed repositories expect growth rates for the next period of between 20 and 100 % per year. Anotjer 40 % expect more than 100 % annual growth. For half of them the number of digital objects exceeds 106.
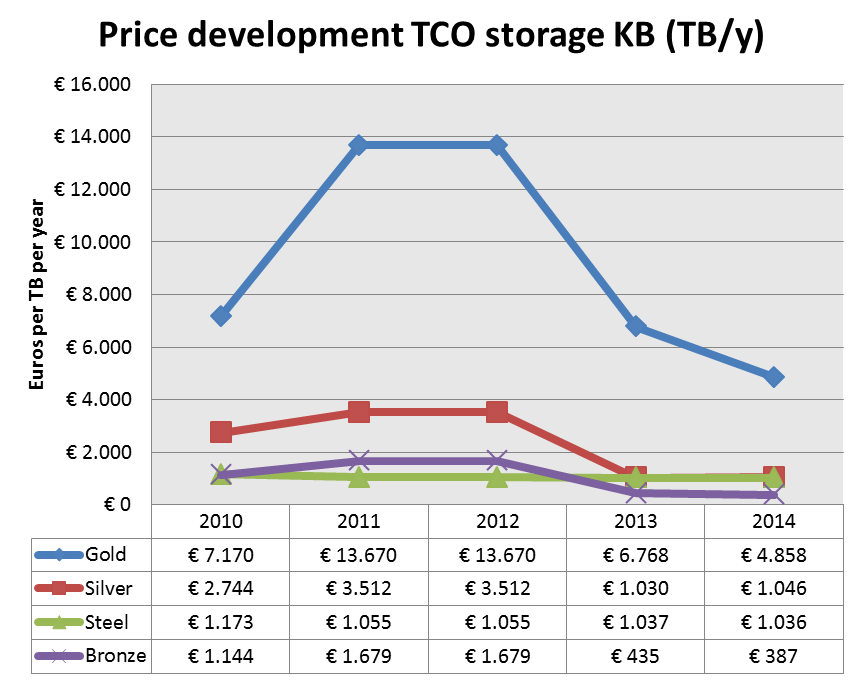
Half of them have a formally declared storage solution policy. This entails measures for integrity checks, interval backups and data recovery workflows. Access and preservation mostly takes place with RAIDs, while back up is in 50 % of the cases on tape (and for the rest Raid 1 and 5).Replication can happen on different devices and different locations. Geo redundancy is very important, as was shown after the earthquake of l’Aquila. In his conclusions on the survey analysis, Silvio Salza underlined that answers in the survey on reliability sometimes lacked credibility and that outsourcing was the big elephant in the room – just like storage in the cloud. He recommends that quantative elements should underpin the architecture design of the storage solutions better, including figures on cost, reliability, availability, replication and lifespan. Next to that, geographical replication and outsourcing are important elements to introduce in many storage policies. Because digital preservation works best if not all eggs are in one basket. - Jeffrey van der Hoeven of the National Library in the Netherlands, KB presented a very clear use case from the National Library in The Netherlands, KB, with some impressive figures. The KB gets more than 4 million web visits per year and stores more than 8 million newspaper-pages and 2,1 mln parliamentary papers. Newspapers are 60 % of their stored items, pictures around 27 %. The overall prospect is that 1 PB of stored data will be reached in 2018, roughly doubling the current level.Main challenges are volume (size and number of files), type of data (structured / unstructured), growth rate, availability vs preservation, cost per TB. Storage takes place inhouse and off-site (back-up) and the storage management differentiates between 4 levels: gold, silver, steel and bronze, each with a different service level (speed and medium used) and cost.Storage costs vary greatly over the years and have been subject to different modelling, but has remained in the middle levels of third party storage providers:
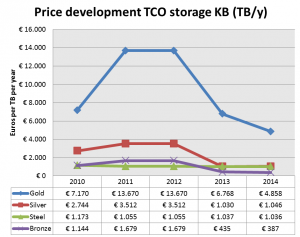
In his concluding remarks, Jeffrey van der Hoeven pointed at the advantages of cloud solutions, such as: Scalable, Availability, Pay per TB per month, No need for own ICT infrastructure, Less maintenance. But he also warned for uncertain elements such as sustainability, data responsibility and jurisdiction, cost development and continuity, lock-in in case of migration. - Mark van de Sanden from EUDAT explained how EUDAT offers a common data infrastructure across Europe within a network of 26 partners across 13 countries. Pillars in the approach are easy-to-use, user-driven and sustainability. The CDI is a network of distributed heterogeneous storage systems for which EUDAT is not developing new technologies. EUDAT services are based on existing (open source) technologies, adapted to EUDAT needs. Services are built on top of existing storage and computing infrastructures.
EUDAT is regarded as a high-profile initiative, technology choices made influence the potential user base, sustainability and training, EUDAT is not developing new technologies.Mark van de Sanden pointed out how technologies are carefully selected on basis of Functional and non-functional requirements, Proprietary versus non-proprietary, Closed versus open source and warned that selection of a specific technology always creates a level of lock-in. EUDAT also offers services to individuals and has embraced the principles of citizens science.
Based on his presentation, a discussion developed on the pros and cons of cloud storage. - Julio Carreira from ESA focused even more deeply on cloud storage in his talk on the work at ESA by RSS (Research Service Support), mainly in support of the Earth Observation research work. This requires big data storage in the order of magnitude of 600 TB, adding 50 TB per year. The solution as to build a data-farm, based on distributed file systems accessible from all work stations and that can be deployed on top of any pre-existent file system. It takes care of mirroring and replication, load balancing, storage quotas and ACLs for user access to data.According to Julio Carreira, the RSS DataFarm allows much more flexibility than before in accessing data. For example, it is now possible to ingest data directly from the former G-POD dedicated storages into the RSS WebMap Server, with no need to copy data on a local storage. The same applies to SSE, KEO and the other RSS environments. Other benefits brought by the DataFarm are optimized storage space utilization, aasy access control and aasy scalability.RSS DataFarm moves a step towards the Cloud as well. Its novel RSS infrastructure model has been naturally extended to the Cloud, constituting a robust and scalable basis for providing more efficient and flexible support to EO data users in the coming years. Right now, ESA has 15 TB in the cloud and carries out many tests on reliability, security, stress testing on performance and backup and for cost modelling. By carrying out these tests, Carreira adds: “We are creating policies and rules to mitigate the main risks of having the storage on the cloud”.
- In his concluding remarks, David Giaretta project manager of APARSEN, pointed out how different situations have been required different solutions and that there is great merit in bringing these experiences together. A central theme is clearly cost modelling and cost management, especially against the background of scalability. Giaretta appreciates the great variety of experience as assembled in APARSEN and expects that this will be a valuable source of guidance for other APARSEN members.
[/reveal]
Long Term Preservation and Digital Rights Management
10th March 2014
Digital Preservation is all about long term accessibility, re-usability and understandability of digital objects. Environments and objects with digital rights management, pose extra challenges for Digital Preservation. The APARSEN project has researched in-depth the risks, challenges and approaches for preservation of DRM-systems and explored approaches and measures to ensure longterm accessibility of objects. As part of the project, risk assessments and surveys were held and use cases made. Come and listen to the results of this research in our webinar.
The speaker’s programme was:
- Simon Lambert, APARSEN Coordinator: “General introduction to APARSEN and how DRM fits in”
- Stefan Hein, German National Library DNB: “Introduction to Digital Rights and their representation; Introduction to DRM concepts, classification and risk analysis”
Download: [Download not found] - Sabine Schrimpf, German National Library DNB: “Use case: German National Library (DNB)” Download: [Download not found]
- Kirnn Kaur, The British Library BL: “Highlights from the survey and recommendations” Download: [Download not found]
- Simon Lambert, APARSEN project Manager: “Conclusions for APARSEN”
Moderator: Eefke Smit (STM)
[reveal heading=”⇒ Click here for a Short summary of presentations and discussion“]
Keywords: Digital rights management, digital preservation, ingestion checking, rights expression languages, metadata, authenticity, access, reuse
In the following presentations, the APARSEN speakers elaborated on:
- DRM concepts, classification and risk analysis
- A case study from the German National Library DNB
- Survey and recommendations from APARSEN
After the APARSEN presentations, Simon Lambert summarised the importance of the findings for the future APARSEN VCoE and the demand for training material to make DP-professionals better aware of the best ways to treat DRM measures.
- In his introduction, Simon Lambert (STFC, project coordinator) explained how digital preservation has to take into account any DRM measures on objects that require preservation. In some case it may impede future access and re-use of the preserved object if DRM mechanisms are not properly recognized, described or removed in case the access tools are no longer available. In the context of APARSEN, the variation in DRM systems were explored and classified and a preservation risk analyses was undertaken.
- Stefan Hein, German National Library (DNB) gave a thorough introduction to the concepts and manifestations of DRM-tools and systems. DRM covers the management of access and use rights to digital material and in this study in particular the focus was on the digital tools and techniques put in place for this. Stefan Hein presented a classification of 4 different of such DRM-categories including their risk level in terms of digital preservation:
 The lightweight DRM measures, such as digital watermarking and tracking devices that enable to monitor illegal use, have no risk for digital preservation, as they usually do not restrict access as such. The medium risk categories usually embed a DRM-measure into the encrypted object (a password is needed for decryption) or into the data stream on the data carrier (a anti-copy protection), which can raise a challenge for the Digital Preservation; should and can it be removed or not. Complex DRM systems often have elements embedded in the object and external components (software and/or hardware) are required to access the object. Kindle books are an example.In the discussion following his talk, Stefan Hein shared the observation that increasingly content producers seem to favor the more complex DRM systems that are embedded in software or hardware (such as readers and tablets) – especially for e-books and in the film and video industry. This is likely to pose an extra challenge in Digital preservation.
The lightweight DRM measures, such as digital watermarking and tracking devices that enable to monitor illegal use, have no risk for digital preservation, as they usually do not restrict access as such. The medium risk categories usually embed a DRM-measure into the encrypted object (a password is needed for decryption) or into the data stream on the data carrier (a anti-copy protection), which can raise a challenge for the Digital Preservation; should and can it be removed or not. Complex DRM systems often have elements embedded in the object and external components (software and/or hardware) are required to access the object. Kindle books are an example.In the discussion following his talk, Stefan Hein shared the observation that increasingly content producers seem to favor the more complex DRM systems that are embedded in software or hardware (such as readers and tablets) – especially for e-books and in the film and video industry. This is likely to pose an extra challenge in Digital preservation. - Sabine Schrimpf, German National Library (DNB) presented a very clear use case from the DNB, the German National Library. Since 2012 the DNB has been checking all material ingested into their archives for DRM measures and this happens automatically. DNB requests the content providers to deliver them the material DRM-free so that the authenticity of an archived object can be guaranteed. DNB will also re-examine all archived objects that were ingested before 2012 to see if any DRM measure slipped through. To ensure their long term Digital Preservation, such DRM measures would be removed.Of all PDF objects that were archived at the DNB since 2012, only an extremely low percentage (146 out of 1.6 million) was ingested with unremovable DRM-measures. According to Sabine Schrimpf there is very good collaboration with German publishers and booksellers on delivering DRM-free objects for archiving and on the permission terms for public access to the archive.
- Kirnn Kaur, The British Library (BL) presented the findings of the survey that was carried out for APARSEN and the recommendations from the project. The purpose of the survey was to find out how the participants handle DRM-protected material and the associated rights. The primary aim was to discover how archiving of such objects is dealt with and what is being done to protect the rights information. Repsonse was received from 18 respondents, who asked their responses to be treated confidentially except for four organisations. Participants came from national libraries (n=9), scientific research organisations (n=3), archives (n=2), universities (n=2), one publisher and one project . Geographically, 16 of the respondents were from Europe (Austria, Denmark, Finland, France, Germany, Italy, Netherlands, Switzerland and UK) with two were from the USA.Largely speaking, some 60 % do investigate DRM protection of their archived material, have dealt with such material and make it part of their ingestion process, and indicate that they process and preserve these rights at the object level. Some 40 % do not see DRM as an issue at all.The main recommendation of APARSEN is that DRM-detection should be part of the ingestion process and that ideally, objects are archived DRM-free while the rights to the object are documented and preserved properly, in a transparent way.
A summary of the general overall conclusions are:
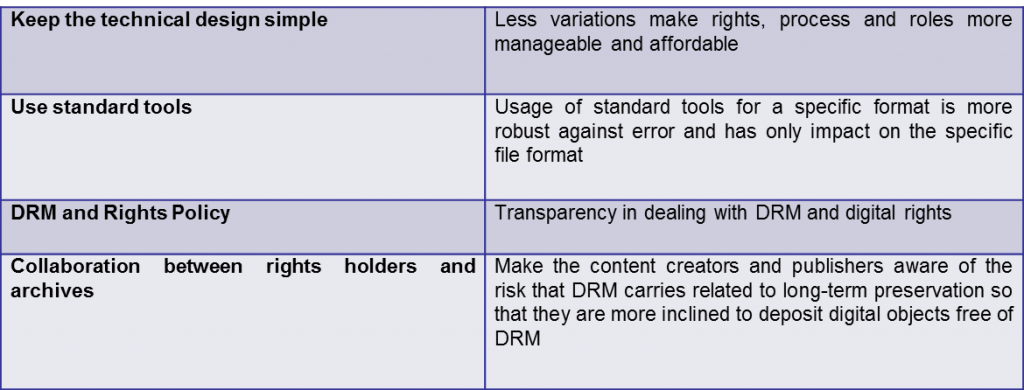
Kirnn Kaur added that good training material on how to treat DRM measures within the business processes and during the whole lifecycle of an object will help increase awareness for DRM in Digital Preservation. There is a role here for the APARSEN Virtual Center of Excellence.

[/reveal]
Certification of Digital Preservation Repositories
9th December 2013
Successful digital preservation depends heavily on the longevity of trustworthy archives. Certification of data repositories and digital archives is a very important step to ensure the long term quality and sustainability of archives and to have a documentable assessment of the solidity and robustness of their working procedures and preservation approaches. Several initiatives have evolved in the recent years to establish good certification internationally. In the upcoming APARSEN webinar the most noteworthy approaches are explained and compared. Among them are the Data Seal of Approval (DSA) by Dutch Data Archive DANS, the ISO-method as tested by the Royal Library KB, and the DNI-standard applied by the National Library of Germany DNB. The APARSEN-project is designing a way forward in which these different certification approaches can be combined and applied to their mutual strength.
The speaker’s programme was:
- Simon Lambert, APARSEN Coordinator: “How Certification fits the APARSEN project” [Download not found]
- Ingrid Dillo, DANS-NL: “Self certification: “Data Seal of Approval approach” [Download not found]
- Sabine Schrimpf, German National Library DNB: “DIN/Nestor approach for certification” [Download not found]
- Barbara Sierman, Dutch Royal Library KB: “ISO approach for certification” [Download not found]
- David Giaretta, APARSEN project Manager: “How APARSEN tries to make ISO, DIN and DSA work together” [Download not found]
Moderator: Eefke Smit (STM)
A video of the meeting is available
[reveal heading=”⇒ Click here for a Short summary of presentations and discussion“]
- In his introduction, Simon Lambert (STFC, project coordinator) explained how important certification and certification standards are for digital preservation as it is the foundation under the issue of ‘Trust’ and helps avoid the basic threat that ‘those to whom we trust our digital assets may let us down’. Consequently, we want to be able to trust a repository via audits, but we also want to have some basic confidence in the quality and process of the audits themselves.
So standards for certification need to be set and processes need to be established. Within APARSEN, three approaches are explored, and all three are discussed this afternoon. These approaches do not compete but rather build on each other, with DSA (Data Seal of Approval) as the basic self assessment, the Nestor approach following the DIN standard as an extended self assessment with more specified metrics and the ISO certificate as the heavy test including a formal audit by external auditors (who have been certified themselves to carry out such audits).
- Ingrid Dillo of DANS, explained the history and current state of the DSA; this data seal of approval was initiated in 2005 and officially ready in 2007. Since then, some 22 organisations have successfully applied this self assessment which involves a judgement by an external reviewer who checks if all documentation is available and if the guidelines have been correctly applied.
Transparency as well as inclusiveness are the main goals of the process, explains Ingrid Dillo, as she regards these as the main building blocks for trust.
Ensuring data formats that can be preserved properly over time is an important element and a question in the audience was raised how to influence data formats for deposits. Ingrid Dillo emphasizes how too much rigor, meaning having to refuse certain formats, can work against itself and that it is a matter of balance: be inclusive for all kind of deposits and at the same time ensure long term preservation by clear requirements on the right data formats.
- Sabine Schrimpf of the Deutsche National Bibliothek (DNB) explained the Nestor Seal, based on DIN 31644. So far, her own organisation DNB was the first one to go through this certification process and the Nestor Seal is now ready for more registrants. In principle, this process should not take more than 3 months and involves 2 outside reviewers. A small fee of EUR 500 is granted to Nestor to keep the initiative going. DNB concluded the process in 1.5 months. Broadly speaking, the metrics in the Nestor approach are specified in more detail, with minimum requirements that must be met. These requirements are available on the nestor website (see the slides) and in the description of the DIN norm (Criteria for trustworthy digital archives).
The nestor approach is also a self assessment, but with two outside reviewers and can be labeled as an Extended Audit if compared to the DSA. - Barbara Sierman of the National Library of the Netherlands (KB) explained how the ISO approach is about a certification standard for digital archives, as well as a standard for the auditing itself.
She explained how important metrics are, to make sure that audits of different repositories are consistent between each other, and that norms and standards are set unambiguously. People want clear yardsticks. For the ISO approach a lot of effort was put into testing the defined draft standards, as part of the APARSEN project: are metrics understandable and usable, is there consistency in the evaluation of the evidence, how much effort and time is needed for a repository and is the standard widely applicable on different kind of repositories?
In total, 7 organisations (4 in the EU, 3 in the US) were involved in establishing the ISO standard 16363, which includes many examples and specifications on how to meet the requirements.
The test audit starts off with a self audit template, followed by a two-day visit on-site by the “auditors”. In real life, the auditors themselves need to be accredited too, to ensure consistency in the certification. These follow the ISO standard 16919 for auditing practices. The 16919 standard is close to formal endorsement upon which the first auditors can be appointed (and certified).
- David Giaretta, technical project manager of APARSEN, explained how APARSEN tries to bring all these approaches together. He uses the concept of a ladder, via which higher levels of specified requirements are reached. The first level in certification is the DSA-approach with a self assessment to make the processes and practices in a repository more transparent to outsiders. Secondly the Nestor Self Assessment, using the formal specifications and metrics of ISO 16363 and DIN 31644. Then, last but not least the formal audit for the ISO or DIN standard, involving site visits by certified auditors. David underlines how improvement plans are an essential elements in certification while at the same time metrics and clear standards are necessary for consistency in judgement. Success will be defined by adoption in the market and by guidance from funders and policymakers who may set certification requirements.
APARSEN aims to help define the certification menu better, including the three steps of a ladder as discussed today, and help repositories to do digital preservation better by helping them to comply to standards set. APARSEN is planning to provide tools, services and consultancy for this, also beyond the horizon of the current project.
[/reveal]
Interoperability and Intelligibility Strategies
8th November 2013
The speaker’s programme was:
- Simon Lambert, APARSEN Coordinator: “The importance of interoperability and intelligibility in Digital Preservation”
Download: [Download not found] - Barbara Bazanella, University of Trento, APARSEN partner on services to support interoperability: “Interoperability Objectives and Approaches” – INCLUDES AUDIO, PLAY THE POWERPOINT IN FULL SLIDESHOW PRESENTATION TO HEAR THE SPOKEN WORD OF THE PRESENTER
Download: [Download not found] - Yannis Tzitzikas, FORTH, leader of the APARSEN workpackage on interoperability: “Interoperability Strategies”
Download: [Download not found] - Johannes Reetz, Max Planck – Plasma Physics Munich, EUDAT: “How EUDAT faces interoperability”
Download: [Download not found] - Simon Lambert: “Impact on APARSEN”
Moderator: Eefke Smit (STM)
[reveal heading=”⇒ Click here for a Short summary of presentations and discussion“]
In the following presentations, the APARSEN speakers elaborated on:
- Importance of concept of performability
- Modelling dependencies
- What can be automated?
- Emphasis on converters and emulators
After the APARSEN presentations, Dr Johannes Reetz (Max Planck Plasma Physics, Munich) of the EUDAT project presented the way in which the EUDAT project faces interoperability issues.
- In his introduction, Simon Lambert (STFC, project coordinator) explained how important interoperability and intelligibility are for digital preservation especially so if digital preservation is defined as ‘operability with the future’, meaning that digital objects must remain accessible, understandable and re-usable. It means that current systems must be able to INTEROPERATE with future systems to guarantee that digital resources remain accessible and re-usable over a long period of time maintaining their meaning and value. The heterogeneity of digital material poses an extra challenge, as well as the fact that this is a global issue, between many different stakeholders. Within this context, it is the role of the APARSEN Network of Excellence to coordinate the definition of the research agenda and drive the development of solutions.
- Barbara Bazanella, in her talk on Interoperability Approaches and Objectives, explained how in their part of the APARSEN work in workpackage 25, a comprehensive inventory was made of all Projects and Initiatives, Scenarios and Challenges, Solutions (models, standards, services) and Objectives and Guidelines regarding Interoperability in Digital Preservation. In total, 64 different projects were assessed and their scenarios and challenges evaluated against each other. From this, 58 different solutions were derived, relating to 13 different scenarios. A Database with these overviews will be made available via the APARSEN Network of Excellence as a collaborative tool to raise awareness and understanding of the interoperability solutions currently available. Main themes in the scenarios are Perssistent Identifiers (PIDs), metadata, authenticity and provenance. Solutions can exist of models, standards and/or services and are being displayed in a matrix, connecting them to the problem domains and discipline specific aspects. Among the main recommendations were:
- Fostering the broad adoption of common standards and specifications reducing dependencies, facilitating the interoperation between systems for the entire digital object lifecycle management process and enabling higher-level services on top of standard compliant systems.
- Promoting the use of appropriate identification systems and their interoperability.
- Promote the convergence towards agreed common policies and governance models, which foster the adoption of interoperability solutions and trust on them.
- Ensuring the necessary long-term financial support and the efficient use of economic resources.
The aim of this initial set of recommendations is to be used to integrate interoperability objectives in the DP research agenda for the future. More specific gap analysis and specific solutions can be found in the full report under http://www.alliancepermanentaccess.org/wp-content/uploads/downloads/2013/03/APARSEN-REP-D25_1-01-1_7.pdf
In the discussion, a debate evolved how to best tackle fragmentation in this landscape of approaches, scenarios and solutions. A lot of expectation was aired about the practical approach of the Research Data Alliance to come to more coherence.
- Yannis Tzitzikas addressed Interoperability and Intelligibility strategies from the perspective of the performability of a certain task on archived material. Core in the approach is applying automated reasoning, so that performability of tools and tasks (on older systems, software, contents in archives) can be checked in an automated way, avoiding time consuming laborious human intervention. According to Yannis, task performability checking is more practical as a method than mandating standards, which is helpful and necessary as well but does not solve every interoperability issue as it does not make vanish all dependencies that occur in interoperability issues. Such performability checking services could assist preservation planning, especially if converters and emulators can be modeled and exploited by the dependency services. As part of the APARSEN work, his team has developed a tool for dependency management under the name of Epimenides, which can evaluate the usability response in an automated way.
A proof of concept prototype has been tested with positive outcomes. Next steps will be the improvement of the system, work with more archives (such as DANS) and develop cloud services.
A deployment for demonstration of Epimenides is web accessible: http://www.ics.forth.gr/isl/epimenides
The prototype system was tested via a questionnaire among 10 early users who all showed great satisfaction on its usability and the results of the task performability testing. In his concluding remarks, Yannis added: The definition and adoption of standards (for data and services), aids interoperability because it is more probable to have (now and in the future) systems and tools that support these standards, than having systems and tools that support proprietary formats. From a dependency point of view, standardization essentially reduces the dependencies and makes them more easily resolvable; it does not make dependencies vanish. In all cases (standardization or not), interoperability cannot be achieved when the involved parties are not aware of the dependencies of the exchanged artifacts. However, the ultimate objective is the ability of perform a task, not the compliance to a standard. Even if a digital object is not compliant to a standard, there may be tools and processes that can enable the performance of a task on that object. As the scale and complexity of information assets and systems evolves towards overwhelming the capability of human archivists and curators (either system administrators, programmers and designers), it is important to aid this task, by offering services that can check whether it is feasible to perform a task over a digital object.
Towards this vision, D25.2 describes how advanced past rule-based approaches for dependency management can be used for capturing converters and emulators, and it was demonstrated that the proposed modeling enables the desired reasoning regarding task performability. This can greatly reduce the human effort required for periodically checking or monitoring whether a task on an archived digital object is performable.
In the discussion, people pointed at how the Epimenides prototype is related to several migration tools developed for Planets that aim to assess the success of different migration strategies.
- Johannes Reetz, guest speaker from the EUDAT project, explained how EUDAT represents an infrastructure consortium of data centers and data projects. The aim is define the use cases for providing services, mostly based on Open Source technology. The adoption of these will help in achieving increasing levels of interoperability between data centres. Common services in focus are safe replication, data storage, AAI, PID, and building a metadata catalogue. Later there will be added Dynamic data, a EUDAT Databox, semantic annotation and workflow tools.
Johannes proved a great supporter of the new RDA initiatives, especially to help establish operational and legal frameworks. Integrity checking for interoperability is key and in an environment with so many stakeholders, common practices need to evolve and common high quality standards need to be applied. For all of this, RDA should offer a good forum which can establish a global approach. Trust is fundamental in digital preservation and via RDA a lot of Trust can be created between partners and across different approaches.
In the discussion the point was made that interoperability is of key importance for data sharing and data re-use.
When prompted about the main differences between EUDAT and APARSEN, Johannes gave his view that APARSEN takes a slightly more research approach with an aim to define the agenda for digital preservation research that can help bring new solutions, while EUDAT seeks immediately implementable practical solutions at a more operational level. Increased interaction between these two working spheres will benefit both for interoperability and data sharing.
[/reveal]
Sustainability and Cost Models for Digital Preservation
13th June 2013
The speaker’s programme was:
- Opening: Simon Lambert, explaining APARSEN and the importance of Cost Models for Sustainability
Download: [Download not found] - Susan Reilly: Business Models explored in APARSEN
Download: [Download not found] - Kirnn Kaur: Cost-Benefit Models analysed in APARSEN
Download: [Download not found] - Neil Grindley: the 4 C project: Collaboration to clarify Costs of Curation
Download: [Download not found] - David Giaretta: Summary and how these findings fit a Common Vision on Digital Preservation
Moderator: Eefke Smit (STM)
[reveal heading=”⇒ Click here for a Short summary of presentations and discussion“]
- In his introduction, Simon Lambert (STFC, project coordinator) explained how important cost models are for the sustainability of digital preservation initiatives and their continued existence in the future. With a substantial share of those costs lying in the future, the undetermined timescale of digital preservation poses a challenge in itself. As well as the definition of future benefits. Transparency of costs are important for informed investment decisions and so are business models that clarify future benefits.
- Susan Reilly (LIBER, WP 36 Business Models) presented the results of the APARSEN WP on Business Models. For this another survey was held, with its main focus to ascertain the readiness of research libraries in Europe to invest in sustainable digital preservation. Recognising key-benefits and incentives by decision-makers is essential. Among drivers and benefits, increased use of content scored highest, while there seemed to be less (too little ?) awareness for the accountability for keeping digitized content safe and re-usable, nor for the legal obligation. Susan Reilly therefore posed the question if perhaps mandates on digital preservation should be the first step. The focus for selection of DP-material was found to be low. While 89 % regard DP important, only around 50 % have incorporated DP in their strategy, mission or vision. Her main conclusions therefore are that further work needs to be done to promote DP to decision makers, and that new revenue streams may be required on a greater scale than currently for sustainable DP. She adds that the idea of collaboration/cooperation between organisations with resources and know-how in DP is gaining ground.
- Kirnn Kaur (BL, WP 32 Cost Modelling) then explained how in APARSEN in WP32, she has evaluated and tested several existing cost models. A total of 8 different models were compared; most of them focusing on costs as related to measuring activities, with 2 also paying attention to benefits (DANS and KRDS). 3 Models were selected for further testing: DP4lib, DANS and LIFE3 and a survey was done (101 respondents).The survey showed that 63 % of respondents would prefer to use a cost model that has been tried and tested by similar organizations, 55 % seek a cost model that has a scope fitting their purpose and 44 % would like a model that is adaptable and easy to use. The main results from the survey mean that cost models need to be validated, cover the digital preservation lifecycle, are easy to use and freely available. The survey also made clear that cost models are not much used for controlling costs, but rather to get more clarity on costs.In the question and answering session, some comments were made on how to promote more attention for the cost element of Digital Preservation, especially in organisations that also carry out other tasks in their core mission. Kirnn Kaur would recommend for absolute beginners in this area, to make a first start by using for example LIFE3 as it is relatively simple in its set-up.
- Neil Grindley was the guest speaker in this APARSEN webinar and explained the recently started EU-funded Project 4C: Collaboration to Clarify the Costs of Curation. The project aims to identify where there are gaps in the current provision of tools, frameworks and models. By filling these gaps, the purpose is to help make organizations invest more effectively in digital curation.The project will compare cost models and specifications, will propose standard terminology to make costs better comparable and to set up a Curation Costs Exchange (CCex). One of the first steps of the project is to simply start gathering curation cost data. The CCex will aim to capture calculation processes, metrics, effort statistics, value calculations, from stakeholders in order to underpin future activity with empirical knowledge.In the discussion and comments section, Neil Grindley remarked that APARSEN en 4C could benefit a lot from good collaboration, also in view of its longer term aims after the conclusion of the project, possibly via the foreseen APARSEN Virtual Center of Excellence.The discussion afterwards focuses on what the most successful agenda setting actions are for key decision makers. Emphasis on business models with their benefits, drivers and incentives, will probably work better that a single focus on costs. Reilly believes that mandates and legal measures probably work best.
- David Giaretta made the closing remarks and emphasizes how it took a high frustration level to get proper tests for cost models in place – and how that shows the need for better availability and use of cost models. The evidence-based work now available can now facilitate significant progress in this area.
[/reveal]
Sustainability in Digital Preservation through Interoperable Persistent Identifiers
15th February 2013
This webinar featured sustainability and trust issues by means of persistent identifiers (PI) and how to solve the existence of many different PI systems in digital preservation environments. Within APARSEN a demonstrator is being made available for a PI Interoperability Framework to ensure compatability of several identifier systems. Gues speakers from EUDAT and EUROPEANA explained how their projects deal with persistent identifiers.
The speaker’s programme was:
- Why PI’s are crucial in Digital Preservation – Simon Lambert, Science and Technology Facilities Centre – STFC
Download: [Download not found] - PI Interoperability Framework in APARSEN – Maurizio Lunghi, Fondazione Rinascimento Digitale-Nuove Tecnologie Per I Beni Culturali – FRD
Download: [Download not found] - The IF demonstrator available via APARSEN – Emanuele Bellini, Fondazione Rinascimento Digitale-Nuove Tecnologie Per I Beni Culturali – FRD
Download: [Download not found] - EUROPEANA and PI’s – Jan Molendijk, Europeana Foundation
Download: [Download not found] - PI work in EUDAT – Mark van de Sanden – EUDAT
Download: [Download not found] - Discussion
- Conclusions for APARSEN – Simon Lambert – STFC
Moderator: Eefke Smit (STM)
[reveal heading=”⇒ Click here for a Short summary of presentations and discussion“]
- Simon Lambert is the first speaker. His presentation has the title “Why persistent identifiers are crucial in digital preservation?” The main topic of the presentation was placing the topic of persistent identifiers (PI) in relation to the APARSEN Network of Excellence. Also some scenarios in which PIs play a role were described. PIs are an important component of the research topics covered by APARSEN. These are trust, sustainability, usability and access.
- The second presentation, by Maurizio Lunghi, provided detailed information on PI-related activities, as carried out in the APARSEN project. The main message was that an “Interoperability Framework” (IF) is a very important component for the realization for “trusted PI interoperability”. The goal of an IF is to provide interoperability solutions and services of PI systems.This framework is based on the following assumptions:
- Entities are identified by at least one PI
- Only so-called “trusted PI systems” are eligible to be part of the IF (the criteria of a trusted PI system is given below).
- The responsibility to define relations among resources and actors is delegated to the trusted PI systems.
- Digital preservation issues are not directly addressed.
Trusted PI systems have to meet the following criteria:
- Having at least one Registration Agency
- Having one Resolver accessible on the internet
- Uniqueness of the assigned PIs within the PI domain
- Guaranteeing the persistence of the assigned PIs
- User communities of the PID should implement policies for digital preservation (e.g. trusted digital repositories)
- Reliable resolution of the identifiers
- Uncoupling the PIs from the resolver
- Managing the relations between the PIs within the domain
The relevance for interoperability services in the PI domain is illustrated by a number of use cases. Next to the fact that a number of different PI system do exist (e.g. NBN, Handle, etc.) we can observe that specific unique objects receive different identifiers in the course of time. Registration Authorities are not aware of the existence of multiple copies of digital objects. Interoperability here mainly can be seen as disambiguating the identification of objects.
An IF model was developed as well as a demonstrator-service that shows (1) how related objects stored in different repositories can be identified and (2) how publications of an author (identified by an PI) that are stored in different repositories can be identified. The URL of the demonstrator is: http://93.63.166.138/demonstrator/ (last accessed April 5 2013). The demonstrator was shown to the participants of the webinar and background information was given. In order to enable the interoperability between the diverse distributed repositories a common semantic model has to be used. The so-called FRBR-OO model was selected by the developers of the demonstrator. This model can be used to map a number of metadata schemes used by content providers, such as Dublin Core and Marc,. - The third presentation of the webinar was by Jan Molendijk of Europeana. Europeana was described as an “aggregator of aggregators” and in most cases the objects do not have a PID (yet). Within the Europeana aggregator identifiers are generated based on the dataset ID and object ID. The Europeana community is interested in instructions and background on PIDs. At the moment there is no real need for a “meta-resolver” as the content providers give quite good URIs. But this might change. For EUROPEANA the assignments of PIDs might be something to do in the future.
- The last presentation was from Mark van de Sanden of EUDAT. EUDAT (see http://www.eudat.eu) is a European collaborative data infrastructure. The consortium consists of 25 partners in 13 countries and has five research communities on board. Persistent identifiers are one of the topics of interest for the project. Common services are developed in a number of fields, such as metadata catalogues, data storage, data replication and access and authorisation services. PIDs are a component of this last field of services. A number of partners of EUDAT are part of the EPIC consortium in which approaches concerning the application of PID are aligned. The EPIC consortium uses the HANDLE service to uniquely identify objects.
The participants of the webinar were given the opportunity to react on the presentations. Rebecca Grant asked whether APARSEN intends to create a list of PI systems that are trustworthy. Maurizio Lunghi stated that this not the case. The reputation of a PI system is very much a policy issue. Jan Brase stated that the DOI identifier is not a commercial identifier. It has commercial use-cases, but also a lot of non-commercial ones, such as DataCite. Mark van de Sanden asked which information is stored in the records that are shared and identified by a PI, e.g. information related to access rights. He stated that this should not be connected with PIs and should be considered as metadata. At the moment this discussion is also active within the RDA (Research Data Alliance) initiative, so cooperation is needed. Also Tobias Weigel stated that the outcomes of the discussion are important for the RDA initiative. Maurzio Lunghi said that a PI is not a number, not a simple URL but a service.
The webinar turned out to be a suitable platform to exchange ideas and information concerning the application of persistent identifiers.
[/reveal]
Virtual Centres of Excellence – 2
16th October 2012
This webinar was a continuation of the webinar on October 16 on the same topic. In this webinar, examples and case studies were presented by the Open Planets Foundation and 3DCoform. Matters discussed were on the way they were set up, legal choices made, projections on future income streams and funding, and the best ways to ensure fruitful collaboration between partners.
The speaker’s programme was:
- The APARSEN project – Simon Lambert, Science and Technology Facilities Centre – STFC
- What APARSEN can learn from OPF – Adam Farquhar, British Library – BL
- CoC/ VCoE approaches compared and what APARSEN can learn from IMPACT – Hildelies Balk, Koninklijke Bibliotheek – KB
- What APARSEN can learn from VCC-3D aka 3DCoform – David Arnold, University of Brighton
- Discussion
- Conclusions – David Giaretta, Alliance for Permanent Access – APA
[reveal heading=”⇒ Click here for a Short summary of presentations and discussion“]
- Introduction
Eefke Smit welcomes everyone to the 2nd webinar held by the APARSEN project and explains that the webinar will cover the topic of Virtual Centres of Excellence (VCoE). This is a very important topic for APARSEN as a VCoE needs to be set up. A number of guest speakers have been invited to speak about their experiences in this field so that we can learn from them and look at best practices. - Presentation 1 – Introduction by Simon Lambert
Simon Lambert introduces the APARSEN project and explains why this webinar on VCoEs is taking place. The APARSEN project is a Network of Excellence in Digital Preservation funded by the EC under its FP7 programme. The project commenced in January 2011 and is now almost half way through its 4 year duration. Simon represents the STFC who are the co-ordinating body. The aim of the project is to set up a Network of Excellence by bringing together experts and to defragment the work within the digital preservation sector. The consortium brings together a diverse range of partners and consists of 31 organisations across different sectors including universities, commercial companies, research centres, national libraries and other consortia. There is good international coverage across 16 countries. The objectives of APARSEN cover a broad scope of application domains and a variety of digital material, for example, we are looking at technical solutions, cost modelling and digital rights to cover the whole range of digital preservation activities. A key output is the VCoE.
The general approach splits the work over four streams of activity. In the first year we focussed on issues of TRUST by looking at how we know that digital repositories are trustworthy over time. In the second year we are looking at SUSTAINABILITY, followed by USABILITY and ACCESS.
The VCoE is a key output of the project and is clearly stated in the objectives. The VCoE is related to the common vision of the digital preservation landscape. It brings together capabilities, knowledge and expertise from diverse teams and is a repository of knowledge. There are a number of important questions for the VCoE. Who will benefit and how? Is it sustainable? What are its scope and activities? The relationships with existing coalitions and networks also need to be addressed. This webinar will help to answer some of these questions by learning about the experiences of existing Centres of Competence or Virtual Centres of Excellence. - Presentation 2: Adam Farquhar – What APARSEN can learn from OPF
Adam Fraquhar is Head of Digital Scholarship at The British Library. As co-ordinator of the PLANETS project from 2006-10 the issue of sustainability was considered. The setting up of a VCoE was not within the project DoW but was formed during the project. The project partners still had problems for which solutions were required after the end of the project. These solutions would be valuable to other organisations outside of the project and as a result the idea of the VCoE was finalised and the Open Planets Foundation (OPF) was created. The OPF is a not-for-profit, membership supported organisation. The mission of the OPF is to ensure that its members around the world are able to meet their digital preservation challenges with solution that is widely adopted and actively being practiced by national heritage organisations and beyond. The focus of the organisation stretches beyond the cultural heritage sector and is focussed on the practical challenges within digital preservation. The OPF engages with and brings together experts in this field and has made progress over the last couple of years. There is an obvious synergy between OPF and the VCoE within APARSEN and they will work closely together over the coming year.
The idea of the OPF was considered half way through the PLANETS project. A number of options were considered including for-profit organisations who offered products and services but this was not considered a good fit with the project team. The not-for-profit approach was decided upon. Background research was carried out looking at different organisational models e.g. membership and charitable organisations. It was decided that a corporation limited by guarantee and located in the UK would be the best option. The OPF was set up as a not-for-profit organisation which has further restrictions within its Articles of Association. Getting the OPF up and running proved to be hard work! The structure of the OPF consists of a Board of individuals who are elected by members. This allows business experts to be brought in to provide support and advice. Legal advice was sought to set out the articles and reach final agreement. There were a number of key decision points including revenue commitments from organisations to cover staff costs, agreement on vision and objectives and the business model. A two-tier pricing system with affiliated and full membership was adopted. Membership fees supported core staff costs with a 1 year and 3 year discounted fee structure as the DPC model. Another revenue stream includes project funding which accounts for 25% of total funds. The membership model has recently been reviewed for expansion with a transition from the current model to a services model with a sliding scale for membership.
The lessons learned include the need for hard work. This should not be underestimated and should include work on strategy as well as logistics with some activities being outsourced. The strong relationships built up over the PLANETS project were essential and a good starting point with year on year commitment from members. The right business model and revenue mix were key to the sustainability of the OPF. Also, it should be noted that not for profit is not the same as no margins as revenue must be increased and a reserve must be set aside.
Eefke Smit asked how many members they had and the number of staff. Adam stated that OPF had approximately 20 members and staff numbers were 3 core staff with 2 project support staff. Wouter Los asked what was different between an organised network and a legal entity to earn money. Adam gave the reason that a legal entity was required in order to engage in project work. Wouter also asked if an assessment was made on membership i.e. were members vetted? Adam stated that there were no competency requirements and they encouraged those who wanted to learn. David Arnold asked about the breakdown of membership turnover, revenue and project funding and whether there were problems with partners being OPF members as well as project partners. Adam stated that membership revenue consisted of 75% with 25% from projects. Membership turnover was very low. Competition between organisations can be a problem in project work but hasn’t been. There is a high level of transparency with OPF bringing competency around technical solutions and being involved in dissemination activities. A good example is SCAPE where you have partners who are both OPF members and partners within the project, for example The British Library. Hildelies Balk agreed that within SCAPE it was extremely useful to have OPF as a member for dissemination. The EC, however, requires a separate identity for SCAPE and the OPF. The problem is that resources can overlap in some cases, however, competition in acquiring projects is not an issue. - Presentation 3: Hildelies Balk – Centres of Competence (CoC)/Virtual Centres of Excellence (VCoE) approaches compared and what APARSEN can learn from IMPACT
Hildelies Balkis in charge of research projects at the KB. Hildelies started with an overview of CoC/VCoE common characteristics and observations and then went on to the recommendations from the IMPACT project. The background of CoC/VCoE is that within the FP6 programme the OPF was set up as a sustainable organisation within the PLANETS project of its own accord although there was no obligation to do so. However, under FP7 there were obligations to build either a sustainable Centre of Competence (CoC), Virtual Centre of Excellence (VCoE) or Virtual Network of Excellence after the end of a project. In future there will be important roles for CoCs. Currently APARSEN is one of six (others are OPF, PrestoCentre, Impact Centre of Competence, VCC-3D, V-MusT.net) and collaboration between these VCoEs has been advocated by the EC. We need to look at how we can work together and what we can learn. A White Paper is to be written for the EC on current best practice. The benefits are that there could be access to more funding by sharing information and looking at areas of potential collaboration. The sharing of information is a key area with the most interesting aspect being how we keep these Centres alive? The common characteristics for these Centres are that they are all not for profit; their income is a mix of membership, paid services and projects; they have a small number of core staff; their website is the main hub; there is strong buy-in from the original consortium which ensures their success. Initial observations are that opportunities for revenue are limited in the digital preservation field when compared to digitisation where there are more opportunities. V-MusT.net has been the most enterprising Centre as they have generated revenues by initiating new projects in the museum sector. IMPACT has been the most active in engaging commercial partners. OPF has the strongest community in the digital preservation field. VCC-3D has a strong emphasis on practical deployment of 3D documentation and training.
APARSEN can learn from the IMPACT Centre of Competence where OCR tools were developed. The project bought together libraries, cientists and industry partners. The Centre is set up as part of the non-profit foundation of the hosting organisation (not a separate legal entity, they may consider a Dutch Stichting set up). The governance structure consists of a Board of premium members (9/10) and approximately 40 other members. The management structure consists of 3 core staff with business development distributed amongst the Board members who have good networks. The offices are based in Madrid with website services shared across one or two other sites. The business model consists of membership and pay as you go. There are three customers segments, content holders, research institutes and service providers. Revenues come from membership, fees for services and project funding. The Business Model Generation (www.businessmodelgeneration.com) method was used to gather ideas and to find the commitment from participants to build the business model. Complementary business models were developed for the three customer segments.
Success factors in building the IMPACT CoC were discussed next. These included commitment from the original consortium through continuous engagement with all stakeholders. There were good networks which were utilised. Risk is reduced through the distributed organisation and shared costs. Another success factor is the business model with the three customer segments. The support of the EC from the IMPACT project to the CoC has been important. In order to sustain the CoC users have been keen to test the tools and resources provided. There is a good interoperability platform which allows for the tools to be showcased. The CoC has been successful in gaining funding for new projects and has been able to keep costs low.
The challenges include the management of expectations as you may not be able to meet all of them. The integration of tools and services and implementation support is difficult as organisations may not be ready. Another challenge is keeping innovation alive and continuing to identify new customers and stakeholders. For APARSEN it is important to define a role in terms of where you can add value and in which field. Trust and mutual sympathy from with in the project and good relationships as well as defining a sustainable business model are key to the success of a VCoE. - Presentation 4: David Arnold – What APARSEN can learn from VCC-3D aka 3DCoform
David Arnold started by introducing the 3D-COFORM project from which VCC-3D was formed. 3D as a medium is behind digitisation and AV which have a strong presence in the digital media field and the 3D sector is not yet experienced. The remit at project start-up was to improve the tools for 3D documentation of heritage, to link 3D representations to metadata and other information about cultural heritage collections, to communicate and to link through to Europeana. In terms of legacy the establishment of the VCoE was set out as part of the DoW. The VCC-3D is a not-for-profit, Community Interest Company (CIC). A CIC is a business with primarily social objectives whose surpluses are principally reinvested for that purpose in the business or in the community, rather than being driven by the need to maximise profit for shareholders and owners. As a legal entity it can join projects. The core mission of the VCC-3D is to help and advise individuals and organisations make objects and collections available digitally to a wider audience using 3D technologies. To achieve this the VCC-3D provides consultancy and training for organisations in the cultural and heritage industries who wish to use 3D technologies. Costs are kept down by having small core staff and a virtual office. Membership services are provided with some services being charged for to generate revenue. A paying membership scale has not been set up as yet. The sector is fragmented with organisations who don’t hold subscription budgets and don’t generally subscribe to journals and is unfamiliar with paying membership fees. This is a challenge going forward. As a legal entity grants and other funding are actively sought. The company is currently dormant and the virtual offices will hire in services rather than staff, until resources are available, to keep costs down. To raise awareness of the concept exhibitions have been branded as VCC-3D. A preliminary website has been set up.
The challenges are the legal issues related to the set-up of VCC-3D as a separate legal entity and the rights with 3D-COFORM which need to be negotiated. There are also issues with legacy IPR from individual partners who have developed components. The balance between rights issues and legal roles are taking a long time to resolve. The transition to a legal entity is a challenge after the end of the project. An exercise has been undertaken to identify partners as shareholders. For start-up services a member base needs to be established by offering very low cost or free membership until the benefits of membership can be identified. During the start-up period funding is an issue and the general expectation is that partners will donate time which could be used to prepare the newsletter. Some partners have staff who have recently retired or are approaching retirement so could provide auseful source of input although this cannot be solely relied upon. Establishing a presence as a sustainable competence centre in the sector is taking time and it may be a ten year rather than a two year operation. The balance between selling consultancy services and providing some free advice will lead to sustainability. The Commission’s expectations of commerciality are a challenge as in the cultural heritage sector the focus is on community interest and not for profit motives which is very different to the business sector.
Eefke Smit asked how many launching members from within the consortium were members of the VCoC. David stated that 10 out of 19 members had signed up. Hildelies Balk stated that in the 10th call of FP7 there may be funding available to extend the consortium with partners from new European countries. In the IMPACT project, funds were used at the end of the project during the second extensions by using the funding instruments available. David stated that 6/7 activities for extension work had not been accepted by the EC. An underpinning concept which should be considered when discussing groups of CoCs with the EC is the Fraunhofer model of funding institutes which draw a third of their funding from government, a third from projects and a third from selling services. Government funding guarantees a presence which over time allows for on-going work in projects and services which stimulates other activities. It may be worth going to the EC and stating that low level funding is required for Centres of Competence. Hildelies agreed and stated that funding was requested for other CoCs to set up a network. The Fraunhofer model is interesting and other projects, for example, APARSEN, could look at this opportunity. David stated that the background activity in each CoC is needed to ensure survival. The CoC in their own right are required and the EC need to fund the infrastructure. Hildelies stated that this would be looked at early next year. David and Hildelies to discuss further off-line as there maybe other questions. Wouter Los has been involved with a Centre of Competence for European Natural History Museums and can provide contact details. If a co-operation of members is required then you pay for this yourself and you should not ask the EC for money. However, if you are building a new research infrastructure you need to re-organise and transfer the power and money to a new organisation. David and Hildelies agreed. David stated that the expertise and work shouldn’t be lost and a legal entity is needed. - Conclusions by David Giaretta
David started by clarifying where the concept of the VCoE came from in terms of APARSEN. The VCoE came about as part of the strategic plan of the APA (Alliance of Permanent Access) which has been around since 2007/8. The strategic plan included research and then the move into infrastructure. The plan was implemented from 2005 in terms of a number of projects CASPAR, PARSE.insight, APARSEN and SCIDIP-ES. The unit which funded the first three projects is now moving away from digital preservation and interest is now in e-infrastructure.Out of Riding the Wave the research data association was set up on a global scale and looking beyond Europe. APARSEN does not force the creation of the VCoE but is within the plan which builds on a proven track record. Adam’s points about the Board, the pain of setting up the legal entity, funding and other issues are consistent with the APA experiences. David then stated that in order to provoke comment, the EC is provoking fragmentation as there are many projects in digital preservation and each needs to set up to create virtual centres. From a strategic point of view, the EC can stimulate these VCoEs with expectations that 90% may eventually fail. There are lessons we can learn from the business side and we need to fight the fragmentation as imposed by the funders. Currently there are attempts to do this, for example, the Research Data Alliance which is being set up. We should consider what real sustainability is as we may end up with only niche centres with a small number of members. - Eefke Smit ends the webinar by stating that we will be organising more on this topic. A recording and written report will be available on our website. Eefke concludes by thanking all those participating
[/reveal]
Virtual Centres of Excellence – 1
12th September 2012
The webinar featured several VCoE initiatives, from the Open Planets Foundation to VMusT.net, as well as an overview of how VCoE’s can differ in aims, composition and approach. In total 6 of such centers are currently in place in the EU, varying from Centres of Competence (CoC) to Centres of Excellence (CoE). Best practices were listed for setting up, sharing information and staying alive after projects have finished, which is often the biggest challenge. Lessons to learn for APARSEN were listed. This webinar was continued on 16 October, see below.
The speaker’s programme was:
- The APARSEN project and the idea of a VCoE –Eefke Smit, STM Netherlands
- Overview of VCoE approaches and best options for APARSEN – Hildelies Balk, Koninklijke Bibliotheek – KB
- What APARSEN can learn from V.MusT.net – Daniel Pletinckx, V-MUST.net European Network of Excellence
- What APARSEN can learn from the OPF – Bram van der Werf, Open Planest Foundation – OPF
- Discussion
- Summary: How APARSEN can make use these lessons? David Giaretta, Alliance for Permanent Access – APA
Overview presentation available here [Download not found]
The video of the webinar is
Securing Trust in Digital Preservation
11th July 2012
The webinar featured an introduction to the APARSEN network, followed by presentations of deliverables of APARSEN on the peer review of data, authenticity protocols and interoperable authenticity evaluation, and provenance interoperability and reasoning. It was concluded by a presentation of the common vision of APARSEN and a guest speaker presentation of the Open Plantes Foundation by Bram van der Werf.
The speaker’s programme was:
- The APARSEN project – Simon Lambert, Science and Technology Facilities Centre – STFC
- First APARSEN Deliverables on Trust: – Peer Review of Data – Hans Pfeiffenberger, Alfred-Wegener Institut für Polar- und Meeresforschung – AFPUM – Authenticity Protocols and Interoperable Authenticity Evaluation – Silvio Salza, Consortio Interuniversario Nazionale per l’Informatione – CINI – Provenance interoperability and mappings, Yannis Tzitzikas, Foundation for Research and Technology Hellas – FORTH
- A Common Vision for Digital Preservation- David Giaretta, Alliance for Permanent Access – APA
- Cross connections between APARSEN and Open Planets Foundation. Guest speaker: Bram van de Werf, Open Planets Foundation – OPF
[reveal heading=”⇒ Click here for a Short summary of presentations and discussion“]
- Eefke Smit opens the webinar by welcoming everyone and explaining that the aim of the webinar is to have people especially outside of APARSEN get a view to what APARSEN is doing and top stimulate discussion especially with stakeholders outside the project and people involved in other similar projects in digital preservation. She explains that the webinar is here for discussion so she encourages people to participate in the discussion in between the presentations to give feedback and ask questions.
After a quick introduction of the speakers and their presentations Eefke hands over to the first speaker. - Simon Lambert starts the webinar presentations with an “Introduction to APARSEN”. He explains that APARSEN is a Network of Excellence funded by the European Commission under the 7th Framework Programme and runs from 2011 – 2014, coordinated by the Science and Technology Facilities Council (STFC) in the UK. He shows a list of partners and how they are distributed throughout Europe. The objectives of APARSEN are to defragment the research in Europe (giving a structure to the research and development effort in Europe) and lead to a Virtual Centre of Excellence (VCoE). APARSEN identified four core topics (Trust, Sustainability, Usability and Access) which are tackled in the 4 streams Integration, Technical Research, Non – Technical Research and Sustainable Uptake throughout the live time of the project one after an other. When it comes to trust APARSEN follows two aspects: Trust in the data itself and in what has to be done to it. The active areas within the network are certification of repositories, reputation of datasets and related materials, and authenticity and provenance. Simon explains that the webinar is carried out now, because some important results of APARSEN are already available and have to be shared with a wider community. He also gives a short outlook on what comes next in the Sustainability topic in APARSEN (given that the available data can be trusted – what can be done to sustain it): Business cases, preservation services, cost/benefit analysis, transfer of custody (brokerage services) and storage solutions. In the end of his presentation Simons gives an overview of the presentations scheduled next.
Wouter Los points out, that EUDAT and APARSEN are doing similar things and an interaction could be fruitful. He asks if there is an interaction between the projects. Simon answers this as STFC is a partner in EUDAT as well, so there are close links. But while EUDAT is more concerned with building a data infrastructure in Europe (more an R&D project), APARSEN is a network with a wider view. Simon stresses again that there are links and that the interaction is taking place. David points out that Pavel Stranak is from EUDAT. - Hans Pfeiffenberger from the Helmholtz Association talks about the “Peer Review of Data“. He starts with an introduction of the Alfred Wegener Institute and its huge spending on data collection. Hans points out that the funders of Helmhotz expect open permanent access to quality assured data. Hans shows us again Simon’s slide on trust and how the work package of Hans worked on trust in the digital data itself and the trustability of datasets, specifically by assessing the quality of datasets by peer reviews. This kind of peer review for data quality includes classical research articles with data supplements, data papers in “classical” scientific journals and articles about data in “data journals”.
Next he shows the stakeholders (funders’ policies, scientists, data repositories and journals) and explains their interest in the peer review of data. The work package has been looking into the current practice of peer review of research data. Hans points to the deliverable that is available for reading on the APARSEN website. He then tells us that scientists have a positive attitude towards peer review of data, but also fear bureaucracy on obligatory requirements on their data management: “Peer review may grind to a halt”. Several journals already require the availability of data, but peer review is mostly not included in standard peer review, publishers however do have positive expectations of peer review of data.
Hans’ conclusions are that an interdisciplinary exchange of the methods of quality assurance of research data has to be done. Quality assurance is time consuming, so tools are needed to make review of data efficient; also an incentive and reward system should be developed. The results of this work package contribute to the VCoE in that quality of content is a basis for each long term preservation business. Quality is related to reputation and the credibility of data, so unique author identification is necessary. Peer review of data would strengthen the reputation of journals and data repositories. Incentives to publish high quality data can be achieved only if data becomes citable, with provenance being a major source of credibility. Peer review of data has to be made scalable and turned into a business model so it might get implemented. Also a preservation of the tools (software) is required to support the peer review and also allow readers of articles to work with the data.
In the following discussion Birte Christensen-Dalsgaard points out that when you discuss about the quality of data you will probably never come with any scientific input to the quality of data. She explains that we are hearing about provenance and trust in the data set, not the actual scientific validity of the data itself. Scientific validity can only be obtained by a reproduction of the experiment creating the data. So it might be useful to work on a kind of infrastructure that if a data set is confirmed by a different source, it becomes more trusted. Birte stresses that the discussion about provenance and authorship is only secondary to the validity of the actual scientific data.Hans tells that as editor of a journal that it is necessary for reviewers of papers to assess the quality of the scientific data. As reviewers can’t recreate the experiments, they have to get clues from different sources. A main criteria of one senior scientist Hans knows to assess the quality of data is simple “which group took it” relying on the reputation of certain groups to assess the quality. But also statistics have to be made to avoid cheating in science like using the same data but pretending it to be different. Hans cites an example of a German scientist who completely fabricated data to prove that mobile phone radiation is harmful. Simple statistics on the data would show that it is invented, aside from doing measurements again. Birte still believes that the reputation is secondary. Yannis Tzitzikas says that the scientific quality of data, i.e. the ability to reproduce them, could be based on the availability of detailed provenance data (documenting all the derivation process). Birte agrees that the provenance is important and is important work for datacenter, library, university or whoever is assigned responsible for it. David points out that this is a strong level for reputation. The discussion continues after the webinar in emails with Hans pointing out that peer review is not the method of choice for all data, also pointing out that for example in the case of observational data, peer review is much better than doing nothing. Hans points to the forthcoming deliverable in WP26 about “Annotation, reputation and data quality” explaining that the pre-ingest phase is the really interesting part, while the chain of custody and operations done by long term repositories is probably rather boring. Birte agrees on the importance of provenance and context data and that peer review of data will work in certain fields. She explains the idea of having different independent experiments confirm data, pointing to Datacite.
Neil Beagrie asks if we need peer review of all data. The availability of the data itself to readers of a journal might already improve the quality; it does not necessarily always need to be reviewed. Data in data journals that is subject to wide distribution would need to be peer reviewed, but Neil questions if all data has to be peer reviewed. Hans thinks that it would be overwhelming to ask for a review of all data sets especially if no proper tools exist yet to do it in a scaleable manner. Hans tells that presenting too many data as supplementary can be a danger, as in a normal review process not all data can be reviewed, but people might think it is if it is put up as a supplementary to the actual journal paper.
- The presentation of Silvio Salza is about “Authenticity Protocols and Interoperable Authenticity Evaluation”. Silvio cites the OAIS definition of Authenticity, which states that authenticity is judged on the basis of evidence. Authenticity has to be collected in the various phases of the lifecycle of a digital object. The work package 24 proposed a systematic way to collect and preserve authenticity evidence along the whole lifecycle. Silvio says that they identified a large gap between the significant scientific contributions by the research community and the actual practices carried on in most repositories. So the next step is to bridge that gap by designing a simple model for the management of authenticity evidence along with guidelines for its implementation. Silvio shows a model for the digital resource lifecycle. He explains that any transformation connected to lifecycle events may affect authenticity, so all transformations have to be traceable. The model Silvio shows identifies a core set of relevant events and specifies for each event the authenticity evidence to be collected. He tells more details about the Authenticity Evidence Record (AER) and how it is collected in connection with a specific event, thus creating an Authenticity Evidence History (AEH) which is part of the Preservation Description Information (PDI) in the SIP. During long term preservation additional AERs contribute to the PDI of the AIP. Next, Silvio talks about the Authenticity protocols (AP) which is an implementation of the CASPAR proposal and connected to a specific lifecycle event. Silvio next shows the operational guidelines that allow the adaption of the model to the needs of a specific environment. The methodology was tested in case studies in APARSEN with CINI, UKDA and CERN. In a first phase the current practices where analyzed and in a second phase the model was implemented and improvements have been proposed. Silvio points out, that exhaustive descriptions can be found in the work package deliverable to be downloaded from the project website. He shows in a bit more detail the CINI case study on the Repository of Vicenza Public Health Care system. The case studies were crucial to validate the modal, helping to improve it. Feedback from the case studies helped to better understand the central role of authenticity in the preservation process and how it contributes to trust. All the work done contributes to the VCoE by providing operational guidelines based on current standards as well as providing input to interoperability and training/consulting services.
Wouter Los remarks that it is a very straightforward way to tackle these issues, but he thinks that it is necessary to reduce the human scientist involvement to avoid bureaucracy and human errors. The research should influence embedded software and hardware in all stages of the lifecycle of digital data already at the creation (e.g. in sensors that automatically generate these kinds of things).Silvio partially agrees – this is a further step that has to be done later. It’s a delicate task so it cannot be automated now. In a later phase Silvio plans to implement tools, but he is not sure if it will still be done during the course of APARSEN. - Yannis Tzitzikas gives a presentation on “Provenance Interoperability and Reasoning”. He explains that his presentation is somehow related to the previous discussion of automation of provenance. Yannis starts by explaining that provenance is important for reproducibility, data quality, attribution and information. There are several models for representing provenance. Availability of mappings between the models is crucial for interoperability. Several mappings have been made, all based on OPM. The objective in APARSEN was to define mappings between OPM and CRMDig (both very good hubs with mappings to other models). CRMDig is an extension of the CIDOC CRM ontology for capturing the requirements for digital objects. Yannis shows that the data production increases. Digital preservation needs extra data to be stored on top (e.g. metadata, provenance data). In APARSEN they identified and specified inference rules that reduce the amount of data that has to be explicitly recorded or provided, stored and managed, considering also the knowledge evolution over time. Three basic inference rules were identified and a set of basic change operations to tackle the problem of knowledge evolution. The three rules identified are that if an actor carried out an activity, he carried out all of its sub activities, if an object was used for an event, all parts of the object were used in that event, and if a physical object that carries an information object was present at an event, then so was the information object. Yannis presents the application of the rules on an example of aknowledge base containing the activities of writing a paper. While the knowledge evolution is a problem for the use of inference, the work done identified ways to deal with deletions, specifying a number of update operations that allow knowledge updating under the inference rules. The work done with regards to CRMdig can be applied to other models and inference rules as well. The contribution to the VCoE as an output of the work package is that expertise will be provided for the conceptual modeling for provenance, related standards and mappings between them, the inference rules for provenance as well as related implementation issues.
Birte Christensen-Dalsgaard asks if the tools and methodology can that be used on data refinement as well, and not just articles as in the example shown. Yannis explains that the model has also been applied to scientific data and the provenance of processing data from a satellite to an archive center.
This concluded the block of presentations of APARSEN deliverables. - David Giaretta talks next about the “Common Vision for Digital Preservation” of APARSEN. He first investigates the question about what is a common vision. APARSEN will get a solid vision until the end of the project. A lot of different organizations give input to APARSEN. Different topics have been broken down to individual research silos, which are then grouped into topics. Those should then be result in a virtual center of excellence, training etc. Some of the parts of Trust have been shown in this webinar, some have not been shown yet. David explains that the different work involved in Trust is clearly linked, but we try to tackle it on a smaller level and then integrate it into the topic of Trust, identifying the links that have been worked out in the work packages. The process we use in APARSEN is an iterative process were we try to piece things together, first integrating Trust and work on Sustainability. Once Sustainability work is done it will be integrated with Trust. The same process will continue with Usability and Access. Integration in this sense means identifying links. In this iterative process we will link all of our work together. We are working on a map of digital preservation and identifying the gaps. We need to get a common view on where research in digital preservation is needed. While everyone has a view on a part of what we do, the global view on the “digital preservation animal” is what is missing and what we try to achieve. In the sense of a Virtual Centre of Excellence, we want to get out Tools, Services, Collaboration/Research/Community, as well as Training and Dissemination, Outreach and Consultancy from the Network, figuring out the customers, partners and resources. Currently we try to expose our thoughts on the different aspects of trust to partners outside the project to stimulate discussion.
Wouter Los suggests giving some attention to the strategy how to implement the work that is done. As an example for certification national accreditation bodies are mentioned, Wouter questions if we need a national approach, a European approach or a thematic approach and if we can rely on the scientific bodies to solve it or do we need some reconciliation. Wouter compares the situation to the discussion in the financial sector after the economic crisis. David thinks that there are different views on this – the ISO view done on the national level with agreements between the organizations. ISO’s aim is to make sure that this supports international trade. So something approved in one country is approved in a different one by consistent approval procedures. Scientific bodies can do in the community what they wish, but if you want to be acknowledged on an ISO level, you have to follow the ISO rules. - Bram van der Werf, executive director of the Open Planets Foundation (OPF) talks about the subject of “From R&D to deployable tools and practice”. He explains that the OPF was founded after the end of the Planets project and in part to sustain the outcome of the Planets EU project. Projects are planned to die – they all end at some point in time and leave preservation orphans. Lots of software developed in R&D projects will never be taken into practice. OPF wants to move from R&D to deployable tools showing best practices. Currently there is a big difference between R&D outcomes and what actually gets deployed, even in big memory institutions. Most tools developed in EU projects are mainly prototypes that are not implemented in memory institutions. The problem usually is the requirements vs. what can be sustained. OPF creates interaction between R&D and practitioners through open communities with focus on user requirements, life cycle, maintenance, and sharing instead of re-inventing. The community functions as a substitute for a missing business. OPF created a maturity process to help the membership community to create more mature tools. Bram talks about a methodology used e.g. in Aqua, Scape, Spruce: Analyse the problem in Hackathons and have developers directly work on the problems together with the practitioners where practitioners are ask to bring data and preservation problems. The OPF community features real discussions between developers and tries to create sustainable software using a practitioner’s blog, a preservation wiki and open source development collaboration on Github. To bring the tools from R&D to a potential service the engineering and maintenance part is missing. By creating the communities an awareness of that is created. 80% of the costs come after the development of the tools. The gap between R&D and practitioners is bridged at the hackathons, having practitioners and developers work together. There is also a focus on small and deployable tools (micro-services, agents) instead of frameworks, to decrease the complexity and create things people actually use. Tools need active users, have to be simple and usable for their purpose. They have to be supportable and maintainable, and also be changeable to adapt to changing requirements. The real key to longevity is active users. To strengthen the practitioner community the gap is bridged between R&D and active practitioners in workshops, hack/mash events and by disseminating project results to the community. A goal of the OPF is to provide a stewardship to help mature preservation tools and data, and to help with practical, hands-on, active participation by the involved parties, reaching out to a wider community of stakeholders and acting as a placeholder for long term access issues and linking to solutions/articulating the requirements in and beyond the OPF community. OPF is focused on the part of “how can we keep it” – do we have the ability to keep it or are there any technical obstructions. Bram explains that this is how the OPF relates to other initiatives in the digital preservation world.
Eefke asks how APARSEN and the OPF can work closer together and strengthen the efforts. Bram thinks that components and initiatives would fit in events where people from a user perspective come together with people from a more technical background to solve the problems together. The most important part is to align activities. In the discussions on the creation of tools in APARSEN the OPF could help out in articulating requirements and creating use cases, coming to a more stable and mature process. The problem is in the quality of data and you can only make that better with more mature processes.
[reveal]